
Full Stack Developer interested in making lives better through software
Updated Jul 2, 2024
In the rapidly evolving field of AI, the Retrieval-Augmented Generation (RAG) design pattern has emerged as a solution to enhance the accuracy and relevance of responses generated by Large Language Models (LLMs). However, new models like ChatGPT-4o and Gemini 1.5 Pro can handle much larger amounts of information in a single prompt. This raises the question: Can we skip RAG by just adding all the needed context into these larger prompts? If so, what implications does this have for performance and cost?
The code for this article can be found here: https://github.com/generalui/openai-api-benchmark/
In this article, I evaluate two different approaches to grounding generated content using OpenAI's ChatGPT-4o model. I will use company documents to provide context, aiming to transform ChatGPT into an expert on the internal processes of GenUI. The primary goal is to ensure that the generated answers from the model are more contextually relevant and factually accurate when prompted about GenUI specifics.
A set of 40 questions relevant to GenUI's internal processes was selected from the new employee handbook and onboarding deck.
This approach involves appending all relevant context directly into the model's prompt. The steps are:
This method utilizes OpenAI's vector stores to upload and create embeddings of custom files. This method embodies the principles of RAG, integrating retrieval mechanisms to augment the generation process. The steps are:
To compare the effectiveness of the inline context and vector DB approaches, BLEU and ROUGE scores are used as evaluation metrics. These metrics quantify the accuracy and relevance of responses by comparing generated answers to reference answers.
By employing these metrics, the study aims to quantify the accuracy and relevance of responses generated using both methods.
For an in-depth look at how the results were obtained, you can review the Jupyter notebooks hosted in our research repository.
Table 1. Performance comparison
| Model | Inline Context | Vector DB |
|---|---|---|
| BLEU Score | 0.265685 | 0.227175 |
| ROUGE-1 | 0.45494 | 0.425944 |
| ROUGE-2 | 0.304204 | 0.274646 |
| ROUGE-L | 0.396724 | 0.334743 |
As seen in Table 1, the inline context method consistently outperformed the vector DB method across all metrics, suggesting better retrieval of accurate and relevant answers. However, the difference is slight, suggesting both methods are close in overall performance and could be viable options depending on specific use cases and requirements. Interestingly, while both methods produce the correct answers, the Vector DB method tends to provide more verbose answers overall which might affect the BLEU and ROUGE scores. Take question 15 “What are the paid holiday benefits provided by GenUI? As an example, both results for method 1 and method 2 focused on the holidays rather than the benefits, with the vector DB method producing a longer answer. A verbose answer is not necessarily a wrong answer, after all the level of verbosity is dictated by your business needs but is worth mentioning, as this affects the scores.
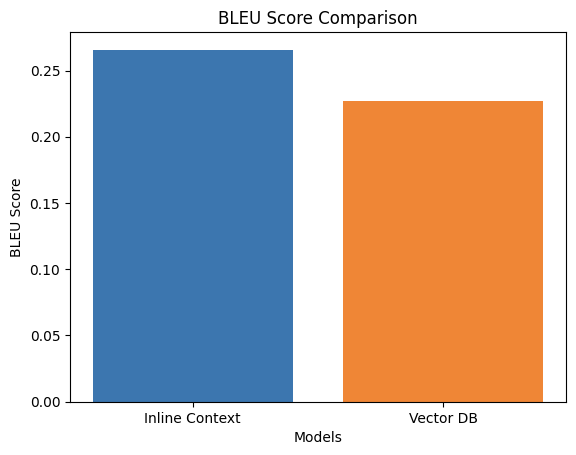
Figure 1. BLEU score comparison
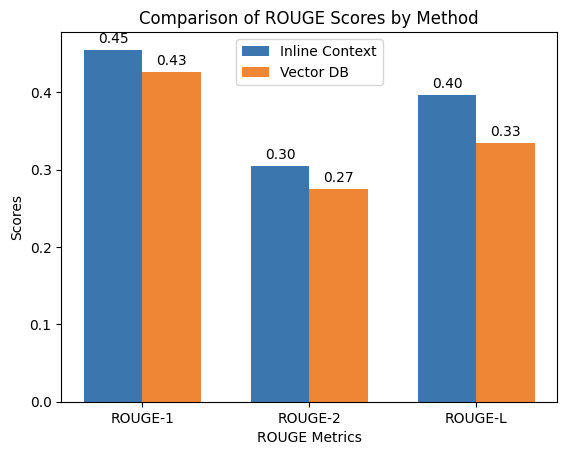
Figure 2. ROUGE score comparison
Table 2. Cost comparison
| Model | Inline Context | Vector DB |
|---|---|---|
| Avg. Prompt Tokens | 20274 | 16884 |
| Avg. Input Cost | $0.101 | $0.084 |
| Avg. Completion Tokens | 146 | 218 |
| Avg. Output Cost | $0.0022 | $0.0033 |
| Avg. Total Tokens | 20420 | 17102 |
| Avg. Total Cost | $0.103 | $0.088 |
Cost calculation based on Open AI pricing.
The cost comparison reveals that the Inline Context method incurs a higher cost due to the extensive prompt size required to include all relevant context. Interestingly, the Vector DB method uses a lot more input tokens than one might expect, with the inline method using on average 20% more input tokens. This suggests that at this level of input tokens (~30K per prompt), using OpenAI's vector stores to retrieve relevant context is still adding to the prompt about 80% of the total context. Which does not sound like a compelling benefit if we extrapolate this trend with larger input token counts.
For use cases where the context information is small (within 30K tokens), it seems that if the priority is accurate responses, it is better to append the relevant context directly in a single prompt albeit this approach comes with increased API usage costs.
However, the cost-efficiency of the Vector DB method is still significant, especially for applications where cost is a critical factor. Considering that in terms of accuracy as shown in Table 1, you are guaranteed to get results almost as good as the inline context method with a 20% reduction in API costs.
This experiment does not show a promising benefit between OpenAI's vector stores against using inline context directly. This opens up the possibility to explore much wider input token thresholds.
If we were to increase the context size to 50K, 100K or even 150K tokens, would OpenAI's vector stores still retrieve and append 80% of the total context into our prompts or will it plateau elucidating the benefits of a vector store in the first place?
On the next step of this research we shall increase the amount of tokens to find out how much better it is to insist on a RAG solution by OpenAI's vector stores or if sending all context on a single prompt remains a valid approach to get ChatGPT-4o to generate company specific answers.
Can we help you apply these ideas on your project? Send us a message! You'll get to talk with our awesome delivery team on your very first call.
 Github
Github
 LinkedIn
LinkedIn